
Explorer
Search platform - aggregate and search data from different sources
Explorer
Search platform - aggregate and search data from different sources
Screenshots
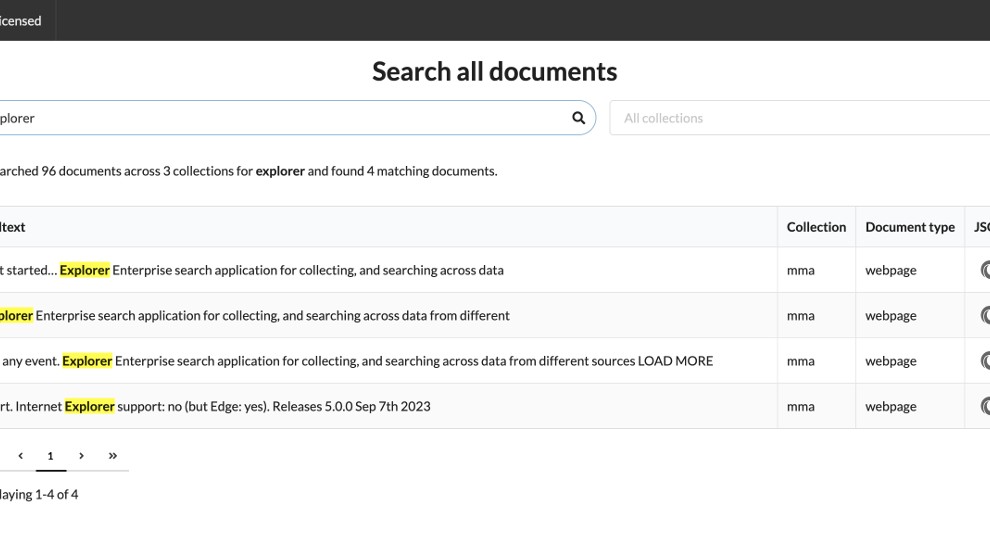
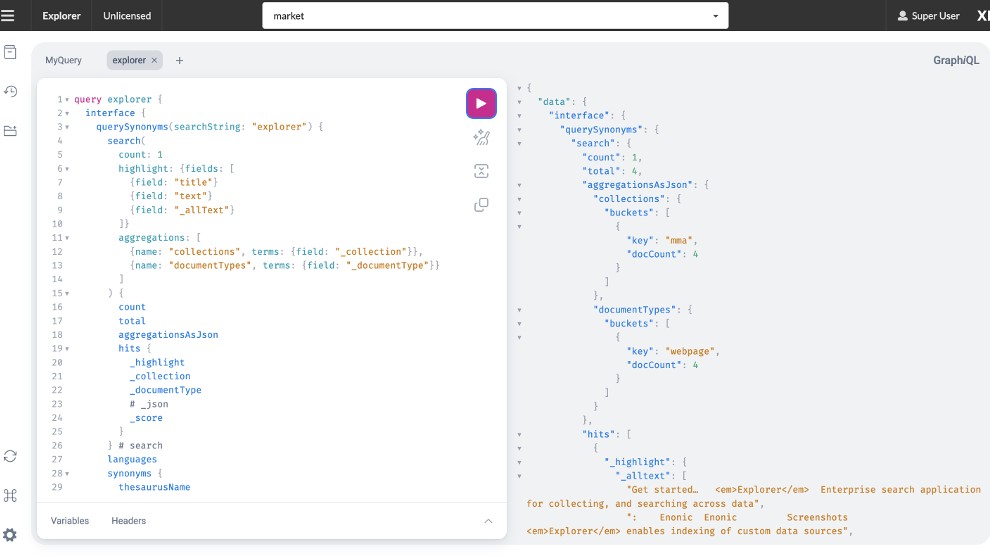
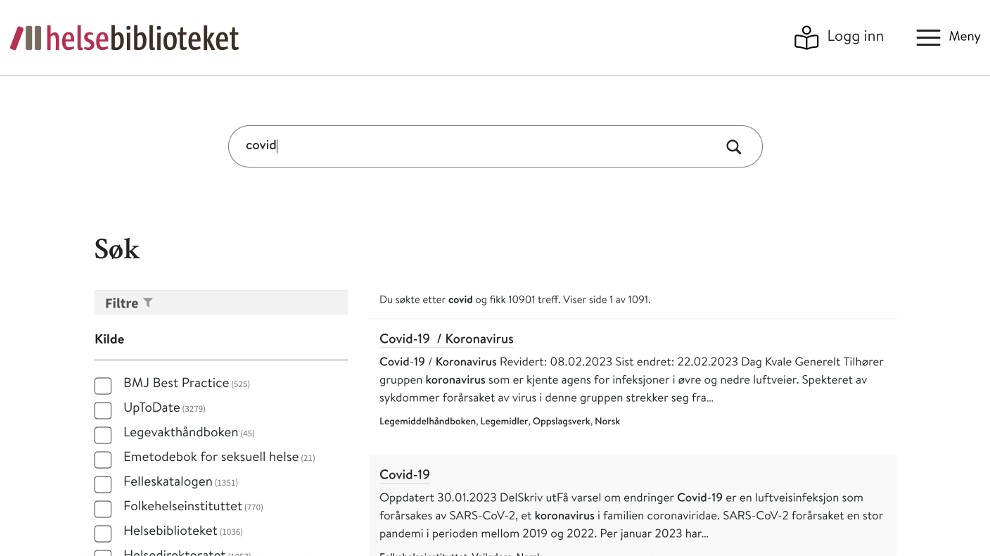
Explorer enables indexing of custom data sources (aka collections). Each collection stores its data in separate Enonic XP repositories, ensuring efficient organization and retrieval.
Back Office
Explorer's admin interface empowers search operators to manage collections, fields, synonym lists, and expose data through "interfaces." Recent updates enhance functionality with sorting and filtering options for the collections table, along with improved synonym handling, including stemming and language-specific synonyms.
Custom Front-end
Explorer does not provide a front-end by itself. Search results can be delivered through custom front-ends of any design. Visit https://helsebiblioteket.no/sok for a live example of its capabilities. The flexibility of custom front-ends is complemented by robust APIs for seamless integration.
Platform
Explorer is more than an Enonic app—it is a platform. Extend it with custom collectors (background tasks that collect data) using custom configuration forms. Updates now include enhanced WebCrawler capabilities, such as support for:
- Custom HTTP request headers and configurable headless browsers.
- Open Graph metadata indexing, including fields like
og:titleandog:locale. - Improved URL handling, normalization, and support for
noindexdata attributes. - Pagination and metadata extraction for better indexing.
Explorer also features expanded document handling with domain and path fields extracted from URLs for improved metadata management.
APIs
Explorer provides powerful APIs for seamless data handling:
- Web API for data ingestion.
- GraphQL API for building front-end search clients, now with sorting functionality and expanded search capabilities.
- JavaScript API for collector jobs running in XP.
User Interface Updates
Recent UI improvements enhance usability, particularly in document search pages and interfaces on the homepage. Interface management has been simplified for easier administration.
Freemium Licensing
Explorer is licensed under the Enonic Licence, allowing everyone to use the platform with some functional limitations. Subscription customers can unlock unlimited collections and access all features. The platform is continuously updated for compatibility with the latest Enonic XP versions, ensuring seamless integration and functionality.
Stability and Robustness
Explorer is built for reliability with:
- Robust handling of scenarios such as
robots.txtparsing errors, duplicate URLs, and invalid HTTP headers. - Improved data protection mechanisms to prevent loss in cases like improper exclude pattern handling or timeout exceptions.
For developers, the platform’s extensibility and enhanced features make it a comprehensive solution for indexing and search-driven projects. Start exploring Explorer’s capabilities today!
Releases
4.8.0
- Support fuzziness in fulltext query
- Support stemming for the _alltext field
- Don't index external redirects
Compatibility:
- 7.16.6
4.7.0
- Support contentTypes with uppercase letters
- Support pathMatch query in admin GraphQL queryContents
Compatibility:
- 7.16.0
4.6.0
- Extend admin gql with queryContents
- Bug fix: Enabled vhost config breaks asset urls
Compatibility:
- 7.14.0
4.5.1
- Bug fix: App won't start without a license
Compatibility:
- 7.14.0
4.5.0
- Dependency updates
- getSites in admin gql doesn't understand projects
Compatibility:
- 7.14.0
4.4.6
- WebCrawler: Fix #932 node.prop('innerHTML') causes Error: Cannot read property "children" from undefined
Compatibility:
- 7.12.2
4.4.5
- Fix: Term boost results are included even when they don't match the searchstring (lib-explorer #316)
Compatibility:
- 7.12.2
4.4.3
- WebCrawler: Doesn't delete old documents matching exclude pattern(s) (#923)
- Webcrawler: HttpHeadersTimeoutException on entrypointUrl causes Webcrawler to delete all documents (#924)
- Webcrawler: Support pagination, but only persist first visit to uri without query and fragment (#926)
Compatibility:
- 7.12.2
4.4.2
- Lower the severity from error to warning for some log messages (#922)
Compatibility:
- 7.12.2
4.4.1
- WebCrawler: Normalize urls without slash to avoid duplicates (#914)
Compatibility:
- 7.12.2
4.4.0
- WebCrawler: Support noindex data attribute (#911)
Compatibility:
- 7.12.2
4.3.0
- Filter the Collections list (#594)
- Make collections table sortable on some columns (#905)
- WebCrawler: Add displayName string in DocumentType (prefer og:title else title) (#896)
- WebCrawler: Support configurable headless browser (url:port) (#899)
- WebCrawler: Use html[lang]/og:locale as document_metadata.language -> stemmingLanguage (#900)
- WebCrawler: Support custom http request headers (#898)
- WebCrawler: Support indexing of Open Graph fields (#895)
- WebCrawler: Add placeholder with example of regexp into the exclude input (#901)
- WebCrawler: Add domain and path field from url (#897)
Compatibility:
- 7.12.2
4.2.0
- Implement #891 Toggle to delete repo when deleting collection
- Fix #890 Deleting collection doesn't delete schedule
Compatibility:
- 7.12.2
4.1.0
- Implement #291 Support sort in the interface GraphQL API search function
Compatibility:
- 7.12.2
4.0.5
- Fix #883 Collections list is flickering while collectors are running
- Fix #884 Non collector task shows up on the status page
- Fix #291 Allow restarting a collector task when previous one is finished
Compatibility:
- 7.12.2
4.0.4
- Fix: WebCrawler handle robots.txt responses without contentType and bodyStream instead of body (#885)
Compatibility:
- 7.12.2
4.0.3
- Fixed: Scheduled collectors fail because task config.name isn't properly removed
- Fixed: Collectors fail for users without super admin privileges
- Note: Collector apps must be updated to use lib-explorer-4.0.3 (or newer) to avoid those bugs
Compatibility:
- 7.12.2
4.0.2
- Fixed some errors related to urls under vhost
- Fixed a bug in the documents API (relevant for collectors)
- Made it possible to log interface query results using http header (explorer-log-query-result: 1)
Compatibility:
- 7.12.2
4.0.1
- Fixed bug when setting up multiple vhosts to the same endpoint
Compatibility:
- 7.12.2
4.0.0
- Added GraphQL search
- Improved UI
- Added DocumentTypes
- Added Documents search page
- Improved search on homepage and under interfaces
- Simplified Interfaces
- Improved Synonyms (language, stemming)
- Documents REST API improved
- Removed Schema page: Fields and Field values (use DocumentTypes)
- Removed lib-explorer.search function (use GraphQL)
- Added data migrations from v1 -> v4 that runs at first start
- Improved Collector class
- Journal can now log information and warning, in addition to success and error.
- Removed deprecated functions collector.register & unregister
- Code converted to TypeScript
- Code test coverage improved
- Synchronized version number between lib and app
Compatibility:
- 7.12.2
1.5.2
- Fix BUG: Editing thesaurus shows synonyms outside thesaurus #427
Compatibility:
- 7.7.2
1.5.0
- Make it possible to select language per collection
- Support stemmed queries
- Add API-key administration (http.header.Authorization: Explorer-Api-Key XXXX)
- Schema validation (Min/max occurrences, valueType)
- Add CRUD Document REST API (webapp/api/v1/collections/<collectionName>/documents)
- Use distributed tasks
- Replace lib-cron with the internal scheduler
- Data migration on first startup based on model number
- Replace collector register with collectors.json
Compatibility:
- 7.7.2
1.4.0
- Make it possible to link a thesaurus to none, any or specific language(s)
- Upgrade to lib-explorer-3.8.0
- * getSynonyms will now filter on languages
- * thesaurus/query({thesauri}) make it possible to filter on thesaurus name(s)
- Upgrade to lib-explorer-3.7.0
- * Added languages field to thesaurus
- * getFields({fields}) make it possible to only get some fields
- * getFieldValues({field}) field can now be an array of fields
- * hasValue(field, values) now applies forceArray to its second parameter
- Upgrade to lib-explorer-3.6.0
- * Generate href for hit tags
- * Require Enonic XP 7.4.1
Compatibility:
- 7.4.1
1.3.0
- Interface data in POST body rather than params.json
- Make sure fragmentSize and numberOfFragments are integers
- Make it possible to select highlight fragmenter, numberOfFragments, order, postTag and preTag
- Upgrade to lib-explorer-3.5.1:
- * Log stacktraces when catching
- Upgrade to lib-explorer-3.5.0:
- * Work around nashorn issue with trunc and toInt
- * Improve debugging with explain and logQueryResults parameters
- * Use highlight fragmenter, numberOfFragments, order, postTag and preTag when searching
Compatibility:
- 7.3.2
1.2.0
- Upgrade to lib-explorer-3.1.0
- Use highlighter provided by Enonic API
- Require Enonic XP 7.3.2
Compatibility:
- 7.3.2
1.1.0
- Require Enonic XP 7.3.1
- Upgrade to lib-explorer-3.0.7
- Upgrade to react 6.12
- Upgrade to semantic-ui-react 1.2.1
- Expose fields to Collector React Component
- BUGFIX Too strict GraphQL Schema lead to missing field values
- Webcrawler collector: Add https:// if no :// in url
- Make initialization a task and show progress in admin app rather than an error
- BUGFIX A collector application can't check the license of app-explorer
Compatibility:
- 7.3.1
1.0.0
- Initial release
Compatibility:
- 7.3.0